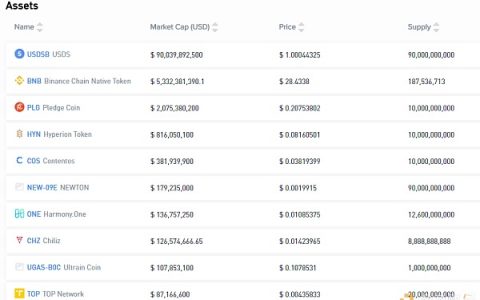
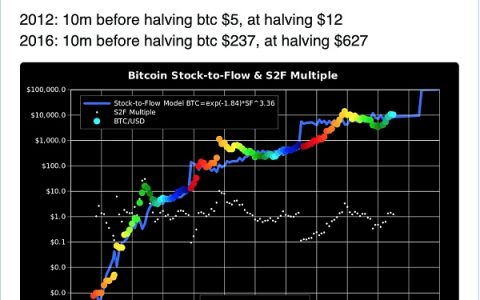
目前区块链技术主要主要面临两个问题:一个是伸缩性,一个是耦合性。
先谈伸缩性问题,我们都知道区块链系统的交易吞吐量普遍不高,增加节点和副本并不会提升交易性能,反而会降低,因为区块链系统中的每一个全功能节点都拥有全量的账本数据。一个分布式系统的性能主要体现在两个方面,一个是读的性能,一个是写的性能,前者是通过replication即副本机制来提升,比如常见的主从备份,一主多备份等。而写性能主要是通过sharding,即分片机制来实现,不同的业务发给不同的节点来处理,每个节点就叫做一个shard,分片机制与副本机制也可以结合起来,一个shard背后有若干个副本,这样每个shard就成了一个集群,这是从高层架构的角度来解决读写性能的一般思路。
所以,我们就可以理解为什么区块链系统做不到很高的交易吞吐量,也就是写性能不高,因为目前主流的区块链系统是一种全副本系统,没有做业务分片,因此读性能超高,写性能却超不过一台单机。而区块链的安全性很大一方面是因为拥有数量众多的副本,普通的攻击无从下手,攻破少量节点也无济于事。

那么,如何在保证高安全性的同时,提高吞吐量呢?
区块链系统存在着一个三元悖论,即一个区块链系统的分散性、伸缩性、安全性,三者不可兼得,最多得其二。
分散性可以用这个系统得以运行所依赖的最少硬件资源来衡量,比如说,这个系统是否能够在普通的个人电脑或廉价的vps上面运行,如果可以,那么它就有可能做到足够的分散性,因为其门槛低。反之,如果一个系统要求高端的服务器才可以运行,那么普通用户就无法运行,这个系统的主要节点必然会被大厂商垄断,这样的系统分散性就低。
伸缩性指的是系统能够处理的业务规模可以通过增加新节点的方式来提升。
安全性指的是系统的抵抗算力攻击的能力(这里主要是对于采用了POW算法的系统而言)
我们在三元概念的基础上,再加一个概念,叫做效率性,其衡量的指标主要是指系统的吞吐量和存储容量,并且提出一个二元悖论,即对于一个单独的区块链来说,分散性和效率性不可兼得,只能二选其一。一个理想的去中心化的区块链项目应该是在能够根据不同的应用需求进行自由的选择。
阿希(Asch)是如何解决这些问题的呢?
从构架上,阿希(Asch)提供了一条公有链和一套应用sdk,这个公有链称之为主链,而使用这个应用sdk可以开发出一个拥有完整、独立的区块链的应用程序,并且这个应用程序可以与主链通过跨链协议互通资产,之所以采用这样的架构,是因为它可以在保证安全性的同时,给用户(dapp开发者)提供在分散性和效率性做选择的权利,同时主链与dapp整体作为一个多链系统来看,是具备伸缩性的。
系统的安全性主要是指共识算法的安全性,Asch系统(不管是主链还是应用链)普遍采用了PBFT优化后DPoS算法,能够容忍最多1/3的受托人节点同时出错,假如某个受托人的节点出错了,那轮到该受托人生产区块的时候,就会缺失一个,并顺延到下一个10秒。假如超过1/3节点同时出错,那么系统将暂停工作,等到足够的节点恢复正常后,系统就可以立即恢复正常。假如1/3以上的节点永远无法恢复(这种情况是存在的,比如他们的密钥丢了),那么系统必须要通过一次软件升级来恢复,并且这个升级不强制所有节点执行,只要部分节点升级,区块生产恢复正常后,通过受托人投票把那些不正常的节点撤销掉,系统就恢复如常了。在Asch系统中,黑客必须要同时获得1/3以上节点的密钥,才能够发动连续攻击,使网络的分叉持续下去,否则系统将通过最长链同步算法迅速消除分叉,分叉之间的差距不会超过1个区块高度,也就是说2次确认以上的交易基本上不可能被回滚。
系统的效率性,是通过提高节点设备要求来达到的。比如说一个高频交易所,可以设置少量节点,要求每个节点都是一个高级服务器,并且每个节点背后都有一个集群来处理和存储业务数据。
Asch整体(主链与应用链)是一个多链系统,每个应用链彼此之间是独立的,也是并行的,虽然每个独立的链是不具备伸缩性,但可以通过增加新链的方式来实现伸缩性,同时也不会影响安全性,因为它采用的共识算法决定了系统不会因为增加链使得算力分散从而导致安全性问题。
一个区块链系统需要足够的分散化,但不是必须要超高的分散化(像比特币那样),很多无政府主义者对联盟链嗤之以鼻,认为这种系统很难抵抗ddos攻击和政府的干涉,但抵抗ddos和政府干涉并不是区块链必不可少的特性。而且抗攻击性可以通过传统的网络防护措施来解决,不是必须要超高的分散化才能解决
最后一个问题,Dapp的性能,阿希(Asch)实现了一个叫做smartdb的工具,它封装了对缓存和数据库的访问,支持不同粒度的自动回滚机制,开发者只需要关心需要增加或修改哪些数据,而不需要关心这些数据是在内存还是磁盘以及对数据的操作是否成功,在smartdb的支持下,Dapp可以做到高性能的同时,又保持代码的简洁性。
从应用开发者角度来看基于阿希系统做开发能得到哪些切实的好处呢?
第一、阿希的每个应用都是由一个独立的链来承载,应用链与主链之间是松耦合的,应用链之间也是隔离的,因此这会带来以下几个个好处:
应用内部的错误与缺陷不会扩散,不会影响到主链,更不会影响到其他应用,不会出现类似DAO的事件;
应用于应用之间是并行的,因此不会去竞争本来就少的可怜的公有链的带宽、存储与计算资源;
每个应用可以自行指定交易所需消耗的费用,一个应用甚至可以选择支持多个币种作为燃料费用,这解决了开发者与用户在成本上的后顾之忧。
第二,阿希的应用并没有采用chaincode的方式,因此是易于升级的。目前很多平台采用的chaincode的机制显然不适合开发大型、复杂的业务逻辑,合约代码一旦作为chaincode被提交到链上,就无法修改了,而稍微复杂的软件都会有漏洞和缺陷,我们也几乎不可能在第一次发布的时候就把系统设计的完美无缺,软件总是需要升级的。当然,chaincode也有其适用的场景,就是一些逻辑较简单的金融合约,考虑到这一点,以太坊提出的图灵完备的语言就是一个悖论了,图灵完备就是为了实现复杂业务逻辑,但由于他们的chaincode难以升级,于是无法实现复杂业务逻辑。
第三,阿希在开发模式上,是选择了框架的方式而不是抽象出一门高级语言的方式。我们希望开发者能充分利用和组合现有的软件系统、组件和库,而不是依赖于一门尚不成熟的高级语言。开发过大型、高性能服务器程序的主要难度不在开发语言层面,而在于架构层面。一个后端程序员拿到需求的第一时间想的问题不会是该设计哪些类或者函数,如何实现算法,他首先要考虑的问题可能是数据库选型以及数据库模型的设计。下面举个实际的例子,来对比下以太坊平台与阿希平台在开发模式选型上的不同的设计原则。
vitalik曾在http://ethfans.org/topics/125里介绍了一个域名服务的伪代码
| data domains[](owner, ip) def register(addr): if not self.domains[addr].owner: self.domains[addr].owner = msg.sender def set_ip(addr, ip): |
看上去很酷,这么简单的代码就实现了一个域名服务。但是稍微有点开发经验的人可能会在接下来的几秒中开始怀疑了,比如,那个domains是保存在内存中吗,程序关闭,数据会不会丢了呢?如果存在磁盘的话,那么这个语言相当于耦合了数据库组件,而且很有可能是一个k-v数据库,如果是一个kv数据库,我以后如何扩展其他字段,如何按不同的字段进行检索呢?这个数据库的容量有多少呢?还有,如果每一个变量都映射到磁盘,那么当我想真的在内存中存储数据,该如声明与定义呢?
我们看看在阿希平台上,我们是如何实现一个类似的应用的。
首先,我们需要定义一个数据模型
| // model/domain.js
module.exports = { |
(注意,这里我们增加了一个suffix字段,用来查询以某个后缀结尾的所有域名)
接下来,我们需要实现核心业务逻辑
| // contract/domain.js
module.exports = { |
第三步,我们要为这个服务增加一些访问接口
| // interface/domain.js
app.route.get(‘/domain/:address’, async function (req) { app.route.get(‘/domain/suffix/:suffix’, async function (req) { |
我们可以看到,这些代码里面涉及到很多编程语言层面以外的东西,比如那个model的schema很可能是在描述一个关系数据表格,app.route.get是创建一个api handler,app.model.Domain则是一个ORM的模型接口。这些都是传统web程序员很熟悉的东西,并且这些代码足够简单,灵活,也是非常具有扩展性的。
根据央行等部门发布“关于进一步防范和处置虚拟货币交易炒作风险的通知”,本文内容来自网络,所有内容只做信息分享学习使用,不对任何经营与投资行为进行推广与背书,请读者严格遵守所在地区法律法规,不参与任何非法金融活动。内容不代表牛谈观点,发布者:小牛,转载请注明出处:https://niutan.com/6680.html